Machine Decision is Human Decision
Decisions seemingly made by machines turn out to be the products of human labour and embody all-too-human failings.
— Anna Greenspan and Bogna Konior Bratton et al. 2025Bratton, B.H. et al. (eds) (2025) Machine decision is not final: China and the history and future of Artificial Intelligence. Falmouth: Urbanomic.
‘Artificial Intelligence’ coined in 1955 through McCarthy et al. 2006McCarthy, J. et al. (2006) ‘A Proposal for the Dartmouth Summer Research Project on Artificial Intelligence: August 31, 1955’, AI Magazine, 27(4), pp. 12–14., proposed that intelligence could be rendered as descriptive of natural reason, and therefore the possibility for a machine to be built to simulate it. The term has since come to encompass a wide range of technologies; becoming as much a cultural, socio-political point of discourse Bareis & Katzenbach 2022Bareis, J. and Katzenbach, C. (2022) ‘Talking AI into Being: The Narratives and Imaginaries of National AI Strategies and Their Performative Politics’, Science, Technology, & Human Values, 47(5), pp. 855–881. as it is a signifier of reproduced uncontroversial ‘thingness’ Suchman 2023Suchman, L. (2023) ‘The uncontroversial “thingness” of AI’, Big Data & Society, 10(2). and positivist technical specifications. At the forefront of public future imaginaries and a disruptive politics that simultaneously demands democratic attention while foreclosing it Garibay-Petersen et al. 2025Garibay-Petersen, C., Lorimer, M. and Menzat, B. (2025) ‘Creating certainty where there is none: Artificial intelligence as political concept’, Big Data & Society, 12(4). is the rise of Large Language Models (LLMs).
Building off this, OpenAI’s scaling laws Kaplan et al. 2020Kaplan, J. et al. (2020) ‘Scaling laws for neural language models’, arXiv. and release of GPT-3 the same year, the highlight of these advancements is anchored in automation; self-supervised learning on vast training data where the model teaches itself, freed of human labour and the demands of social reproductions. Yet this technology also depends on post-training alignment through human feedback (RLHF) which the scaling narrative – driving market forces and the political – consistently backgrounds.
Machine Decision Is Not Final Bratton et al. 2025Bratton, B.H. et al. (eds) (2025) Machine decision is not final: China and the history and future of Artificial Intelligence. Falmouth: Urbanomic. asserts that one cannot adequately grasp AI’s planetary trajectory from within any single geographic perspective. In Shuang L. Frost’s contribution, the Chinese name for artificial intelligence is translated most faithfully as rengong zhineng (人工智能); 人, person or human, and 工, work or labour. Humanmade. This is set against the English compound which implies something alien or entirely Other to humanity; artificial, or even artifice. Frost notes a saying in wide circulation among industry insiders, that current products marketed as AI are almost all human labour and no intelligence.
This essay argues that the labour materially producing China’s frontier AI is more productively represented through the Chinese name than in the English equivalent; the vocational annotators and RLHF workers of post-2022 China are constitutive of machine intelligence, rather than only instrumentalised as its raw material. That the hegemonic Western, English framings render this labour invisible, demonstrates precisely the process of obscuration that the narrative of autonomous machine intelligence depends on to justify its continued expansion of extractive burdens through data centres, energy consumption, and material infrastructure. The human labour embedded in preference rankings and alignment correction is what 人工 has always named, and what this essay through the shift from earlier machine-learning annotation to the current landscape of frontier LLMs aims to engage with.
AI in Geography
Geography’s engagement with AI is at an “early stage” Walker & Winders 2024Walker, M. and Winders, J.L. (2024) ‘Geographies of artificial intelligence: Labor, surveillance, and activism’, Human Geography, 17(2), pp. 227–235.. Their review makes a case for studying AI as a societal transformation, not contained to one subdiscipline but drawn into conceptual and empirical debates across the entire discipline. The argument is well-placed, yet the paper’s own engagement with labour focuses on workers as variables subject to displacement. The question of who builds AI systems receives a single endnote, citing journalism on a “vast tasker underclass” Dzieza 2023Dzieza, J. (2023) ‘AI is a lot of work’, The Verge, 20 June..
They cite McDuie-Ra & Gulson 2020McDuie-Ra, D. and Gulson, K. (2020) ‘The backroads of AI: The uneven geographies of artificial intelligence and development’, Area, 52(3), pp. 626–633. for reference to East Asia, whose ‘backroads of AI’ reads AI’s spatial arrangement through Neil Smith’s uneven development. The framework scales AI geography along a centre-periphery axis with China on the innovation side of the ledger as a major player in redirecting technology flows. Workers appear as casualties and variables along the backroads; the labour that goes into building AI gets no agency and is acknowledged only as “fragments”, structurally subordinated to a sentence regarding disruption.
The framing reflects a broad tendency in human geography to read AI’s labour implications as effects on workers rather than through workers. Writing AI into its artificiality and Otherness (‘thing’ that acts) is useful for a geography of labour, to critique how workers are acted upon by disruption, expulsion, surveillance. Instead I intend to explore workers as agents whose practices materially – and now onto-epistemologically through LLMs – shape the economic landscapes they inhabit.
Labour Geographies of AI development in China
“The relative absence of empirical scholarship from China is problematic because it is the second largest investor in AI behind the USA and makes up a considerable portion of AI development” Wu et al. 2025Wu, T., Muldoon, J. and Xia, B. (2025) ‘Global data empires: Analysing artificial intelligence data annotation in China and the USA’, Big Data & Society, 12(2), p. 2.
Two years on from the same report cited in Wu, Chinese respondents register the highest levels of excitement, trust, and anticipated benefit of any country surveyed; Western comparators cluster around 40% lower when ranking benefits of AI products and services, a gap sustained from 2022 through 2025 Sajadieh et al. 2026Sajadieh, S. et al. (2026) ‘Chapter 9: Public Opinion’, The AI Index 2026 Annual Report. Stanford, CA: Stanford HAI. (p. 365).
Public sentiment on AI: China against four Western reference economies.
Opinions about AI by country, % agreeing with statement, 2025.
| Global | China | United States | Great Britain | Germany | France | |
|---|---|---|---|---|---|---|
| I have a good understanding of what AI is | 68 | 78 | 66 | 64 | 59 | 59 |
| I know which products and services use AI | 53 | 83 | 44 | 41 | 40 | 40 |
| AI has profoundly changed my daily life (past 3–5 yrs) | 53 | 85 | 39 | 35 | 40 | 35 |
| AI will profoundly change my daily life (next 3–5 yrs) | 67 | 89 | 57 | 52 | 59 | 55 |
| I trust AI not to discriminate | 55 | 77 | 37 | 38 | 47 | 38 |
| I trust companies using AI to protect my personal data | 48 | 72 | 33 | 33 | 41 | 31 |
| AI products and services make me excited | 53 | 84 | 38 | 37 | 45 | 40 |
| AI products and services make me nervous | 52 | 40 | 64 | 61 | 46 | 50 |
China highlighted; non-comparator countries from the original Stanford figure omitted for clarity.
Figure 1. Public sentiment on AI: China against four Western reference economies. Opinions about AI by country, % agreeing with statement, 2025. Source: Ipsos AI Monitor 2025 (n = 23,216, 30 countries); adapted from Sajadieh et al. (2026, Fig. 9.1.3).
“Products and services using AI have more benefits than drawbacks,” by country, % of total, 2022–25.
Source: Ipsos AI Monitor 2022–2025; adapted from Stanford HAI AI Index 2026, Fig 9.1.2.
Figure 2. “Products and services using AI have more benefits than drawbacks,” by country, % of total, 2022–25. Source: Ipsos AI Monitor 2022–2025; adapted from Sajadieh et al. (2026, Fig. 9.1.2).
The scholarship that does exist has emerged rapidly since 2023 through place-specific accounts of the workers inside China’s annotation infrastructure. The workers producing China’s frontier AI can be productively analysed along the ‘backroads’ far from view, but uniquely they run through China’s own inland geography. Wu et al. 2025Wu, T., Muldoon, J. and Xia, B. (2025) ‘Global data empires: Analysing artificial intelligence data annotation in China and the USA’, Big Data & Society, 12(2). coin inland-sourcing to describe the geography of this labour, a mechanism by which coastal AI firms – Baidu and Bytedance in Beijing, Alibaba in Hangzhou, Tencent in Shenzhen – channel annotation tasks to provinces like Guizhou, Henan, Gansu, Shanxi, and Sichuan. Atypical of conventional normative offshoring, a state-enforced ‘double wall’ keeps training data onshore with state subsidies underwriting the physical infrastructure where annotation happens. This security stringency also couples with a lack of ‘large Chinese-speaking low-income countries’ to outsource to, making this internal supply chain the unique driver behind China’s AI development.
Chen 2026Chen, J.Y. (2026) ‘Patchworking platforms: on socio-technological infrastructures for AI data labor supply’, Journal of Cultural Economy, pp. 1–21., extending off Wu, argues that it cannot be understood through state strategy alone. Her ethnography traces patchworking platforms: fragmented assemblages of formal employees, office-based informal workers, and home-based freelancers connected through crowdwork platforms and social-media groups. The workforce typology is stratified with formal employment skewing younger and credentialed while home-based freelancers are predominantly women over twenty-five, pushed into informal tiers by hiring platforms that penalise career gaps and missing credentials. The QQ groups these freelancers navigate function as digital laowu shichang (劳务市场), channelling data workers the way physical labour-service markets channelled rural migrants into construction and manufacturing, a pattern echoing China’s unfinished proletarianisation.
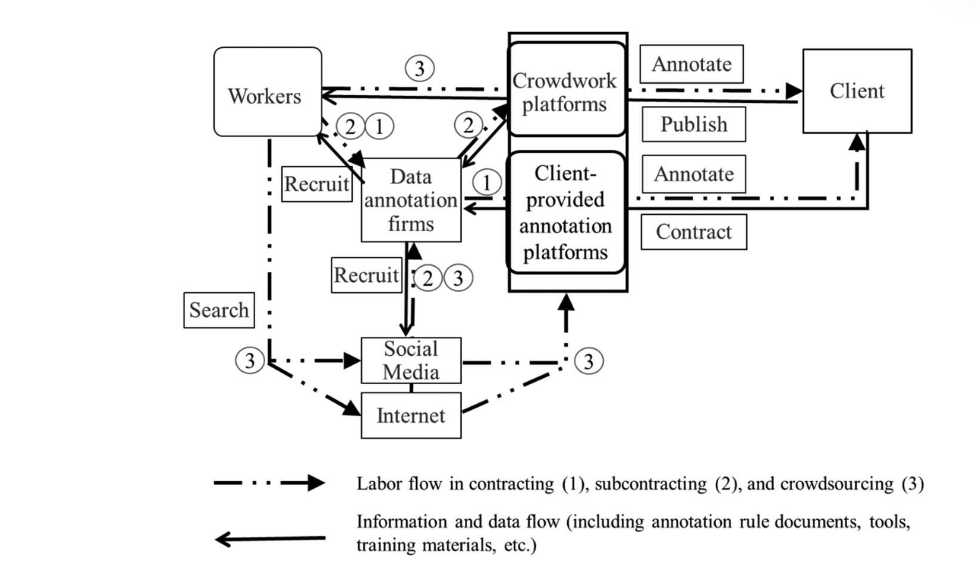
Figure 3. Patchworking platforms: socio-technological infrastructures for AI data-labour supply. Source: Chen (2026).
Subjective annotation
The annotation process and its labour are currently being remade in the era of LLMs. Liu 2026Liu, W. (2026) ‘Biopolitics, immaterial labor, and subjective dilemmas of China’s data annotators’, Labor History, pp. 1–17.’s cyberethnographic approach across two phases looks at QQ annotation groups in Henan and Guizhou townships in 2019 and Xiaohongshu resource-sharing communities in 2024. Outlined is a contrast between earlier low skill, low barrier to entry, bounding box and face tagging annotation, and the natural language processing and preference rating of educated outsourced interns. This transition’s orchestration through state agenda is evidenced by the formalisation of ‘AI Trainer’ as official occupation into China’s national directory in February 2020. Finishing in that same month, another study undertook 8 months of fieldwork as an intern in a Shanghai data labelling team Jia & Yan 2026Jia, W. and Yan, W. (2026) ‘Labor control in cognitive labor and data labeling: the case of AI company N’, The Journal of Chinese Sociology, 13(1), p. 5.. Still focused on pre-LLM data annotation, they name ‘cognitive labour’ to connect worker agency to the technology through their production, highlighting that machine learning itself already distills some nature of the worker.
Towards LLMs, Liu traces a trajectory from ‘bare life’ – annotators sustained at biologically minimal existence on inland wages at the earlier site – toward what Liu identifies as active subjects seeking voice. Crucially the worker voices of the later study still self-identify with language such as ‘cyber-slaves’ and refer to work as ‘just like screwing bolts in a factory’. Their tools of resistance, of ‘living labour’, operate within the logic of capital; continuously reabsorbed through employment structures and biopolitical networks. However, Liu notes a subset of AI trainers have begun embedding “ethical, social, and even humanistic considerations into labelling standards,” contesting algorithmic governance through the cognitive and emotional capacities of their own labour. Semantically, Fu et al. 2025Fu, P., Lin, Z. and Wang, W.Y. (2025) ‘Operationalizing AI governance: data annotation, La Qi and manual alignment in China’, Information, Communication & Society, pp. 1–23. choose ‘positionality’ over ‘bias’ to interpret the ‘deep interpretive process’ of this new form of data annotation as workers renegotiate between corporate, state, and their individual self.
A Chinese journalism article Zhu 2023Zhu, Y. (朱悦 [甲子光年]) (2023) ‘大模型热潮下的实习生…’ [‘Interns in the LLM Boom: All Highly Educated? Yet “Labelling” at Big Tech’], 澎湃新闻·湃客, 12 September. details an industry interview at XingChen Data, where pre-training, supervised fine-tuning (SFT), and reinforcement learning from human feedback (RLHF) each require extensions of past cognitive annotating skillsets in order to fulfil the new requirements of qualitative ranking and at times worker written responses (see Appendix a). In interviews of pseudonymised interns at an unnamed major internet company, their voice emphasises a ‘vernacular’ attention to worker subjectivity Doucette et al. 2023Doucette, J., Hui, E.S. and Friedman, E. (2023) ‘Book Symposium on Eli Friedman’, Asian Perspective, 47(4), pp. 727–741; citing Ngai (2005).. Methods of scoring consist of ‘usefulness, truthfulness, relevance, safety’ (see Appendix b) with multiple workers noting that often they would have to come up with higher quality responses if the model’s answers were too poor (see Appendices c & d). They highlight the importance of 拉齐会 (alignment meetings), a form of pre-training for workers themselves to constantly renegotiate and constitute a standard of ‘quality’. 杨小云 (Yang Xiao Yun) provides a vivid description of this routine:
These standards must be readjusted if found unable to produce expected outputs, something she complains about as meaningless but effective work.
Critically, the process of this updated typology of data annotation replaces the more mundane, objective pre-LLM labour process with a reciprocal subjectivation that aligns the workers with the process as much as workers align the machine. This is interpreted in the article (see Appendix e), particularly using the translated Foucauldian term, 规训 (discipline) Foucault 1975 [1999]Foucault, M. (1975) 规训与惩罚:监狱的诞生 [Discipline and Punish: The Birth of the Prison]. Trans. Liu Beicheng & Yang Yuanying. Beijing: SDX Joint Publishing, 1999., while quoting deskilling and loss of enthusiasm in annotators (see Appendix f). These shifts culminate in a development of the political subtexts the Chinese term 拉齐 points to Fu et al. 2025Fu, P., Lin, Z. and Wang, W.Y. (2025) ‘Operationalizing AI governance: data annotation, La Qi and manual alignment in China’, Information, Communication & Society, pp. 1–23.. Within the cultural context, it refers to ensuring compliance with legal and ethical standards at the state level. Their ethnography positions this alignment as bridging Party-State directives of data security laws and judgements of individual annotators, with classification of ‘patriotism’ and ‘social harmony’ ordered to elevate scores while politically sensitive topics would require lowering them. This goes beyond minimising bias that denotes typical RLHF, and orients towards a reterritorialisation of earlier informal outsourcing and patchworked platforms, into a nationally anchored AI stack with annotators positioned as “frontline enforcers of state rules on data sovereignty” Fu & Lin 2026Fu, P. and Lin, J. (2026) ‘From planetary to state-embedded AI stacks: The re-territorialisation of China’s data annotation industry’, Big Data & Society, 13(1)..
Conclusion
The empirical landscape constructed through labour geographies in this essay surfaces under-researched perspectives on AI from Geography’s prevailing frames. To treat AI labour as a population disrupted by automation, or as a fragment along peripheral backroads, is to concede an autonomy of the technology in the act of describing its costs. The annotation labour constitutive of contemporary LLMs is subjectivity through which the machine’s onto-epistemology is constituted. Likewise the workers themselves are calibrated in their work against state and corporate demands. This loop helps us to better understand geographical dimensions of worker agency, while also recognising that the fetishised narratives of AI as futuristic technology are deeply embedded and produced through recognisable, everyday material infrastructures.
In the inaugural 1982 issue of China’s Artificial Intelligence Journal, Dai Shanren opened the discipline’s founding document by reading AI through Marx’s Grundrisse and Mao’s On Practice. This positioned rengong zhineng as the next stage of human-machine co-evolution with intelligence as the product of collective human labour, ‘intertwined with the cause of communism’ Bratton et al. 2025Bratton, B.H. et al. (eds) (2025) Machine decision is not final: China and the history and future of Artificial Intelligence. Falmouth: Urbanomic.. Chinese AI was, from its inception, steeped in the political economy of the Maoist era, with human labour emplaced in the heart of AI’s intelligence. Beyond linguistic translation, they are wholly different accounts of what, and who, is inside the machine.
Beyond the findings of this essay on post-training and data annotation, there is likely much hidden labour yet unsurfaced, articulated by artist Lawrence Lek within the context of his Sinofuturism Bratton et al. 2025Bratton, B.H. et al. (eds) (2025) Machine decision is not final: China and the history and future of Artificial Intelligence. Falmouth: Urbanomic., which conceptualises a collective of Chinese workers within a movement of overlapping flows of population, products, processes. A faceless hive-mind but with as much worth as the Enlightenment model of the individual to unsettle culturalist, Neo-Weberian explanations for East Asian economic development. By embracing the orientalist cliché he is able to reclaim from Western ontology the metric against which agency is valued, which can at once critique and attend innovatively to radical restructuring of spatial divisions of labour driven by frontier technologies. This attention to flows and fluxes calls for Geography to move at a rhythm closer to AI’s own transformation if it is to duly study its global entanglements and increasing algorithmic and structural enclosure.
Appendix
All extracts from Zhu (2023); translations are the author’s own.
References
- Bareis, J. and Katzenbach, C. (2022) ‘Talking AI into Being: The Narratives and Imaginaries of National AI Strategies and Their Performative Politics’, Science, Technology, & Human Values, 47(5), pp. 855–881.
- Bratton, B.H. et al. (eds) (2025) Machine decision is not final: China and the history and future of Artificial Intelligence. Falmouth, England: Urbanomic.
- Chen, J.Y. (2026) ‘Patchworking platforms: on socio-technological infrastructures for AI data labor supply’, Journal of Cultural Economy, pp. 1–21.
- Doucette, J., Hui, E.S. and Friedman, E. (2023) ‘Book Symposium on Eli Friedman’, Asian Perspective, 47(4), pp. 727–741.
- Dzieza, J. (2023) ‘AI is a lot of work’, The Verge, 20 June. theverge.com
- Foucault, M. (1975) 规训与惩罚:监狱的诞生 [Discipline and Punish: The Birth of the Prison]. Trans. Liu Beicheng (刘北成) and Yang Yuanying (杨远婴). Beijing: SDX Joint Publishing (三联书店), 1999.
- Fu, P. and Lin, J. (2026) ‘From planetary to state-embedded AI stacks: The re-territorialisation of China’s data annotation industry’, Big Data & Society, 13(1).
- Fu, P., Lin, Z. and Wang, W.Y. (2025) ‘Operationalizing AI governance: data annotation, La Qi and manual alignment in China’, Information, Communication & Society, pp. 1–23.
- Garibay-Petersen, C., Lorimer, M. and Menzat, B. (2025) ‘Creating certainty where there is none: Artificial intelligence as political concept’, Big Data & Society, 12(4).
- Jia, W. and Yan, W. (2026) ‘Labor control in cognitive labor and data labeling: the case of AI company N’, The Journal of Chinese Sociology, 13(1), p. 5.
- Kaplan, J. et al. (2020) ‘Scaling laws for neural language models’, arXiv.
- Lee, K.-F. (2018) AI Superpowers: China, Silicon Valley, and the New World Order. Boston, MA: Houghton Mifflin Harcourt.
- Liu, W. (2026) ‘Biopolitics, immaterial labor, and subjective dilemmas of China’s data annotators’, Labor History, pp. 1–17.
- McCarthy, J. et al. (2006) ‘A Proposal for the Dartmouth Summer Research Project on Artificial Intelligence: August 31, 1955’, AI Magazine, 27(4), pp. 12–14.
- McDuie-Ra, D. and Gulson, K. (2020) ‘The backroads of AI: The uneven geographies of artificial intelligence and development’, Area, 52(3), pp. 626–633.
- Ngai, P. (2005) Made in China: Women Factory Workers in a Global Workplace. Durham, NC: Duke University Press.
- Sajadieh, S. et al. (2026) ‘Chapter 9: Public Opinion’, The AI Index 2026 Annual Report. Stanford, CA: Institute for Human-Centered AI, Stanford University.
- Suchman, L. (2023) ‘The uncontroversial “thingness” of AI’, Big Data & Society, 10(2).
- Walker, M. and Winders, J.L. (2024) ‘Geographies of artificial intelligence: Labor, surveillance, and activism’, Human Geography, 17(2), pp. 227–235.
- Wu, T., Muldoon, J. and Xia, B. (2025) ‘Global data empires: Analysing artificial intelligence data annotation in China and the USA’, Big Data & Society, 12(2).
- Zhu, Y. (朱悦 [甲子光年]) (2023) ‘大模型热潮下的实习生:人均高学历?却在大厂“打标签”’ [‘Interns in the LLM Boom: All Highly Educated? Yet “Labelling” at Big Tech’], 澎湃新闻·湃客, 12 September.
人工 Hover any citationHover a citation to reveal its full reference. to reveal its full reference. Figures 1 and 2 rebuilt from the original data; Figure 3 reproduced from Chen (2026). An essay on the labour geographies of AI in China. Machine Decision is Human Decision, by blu.